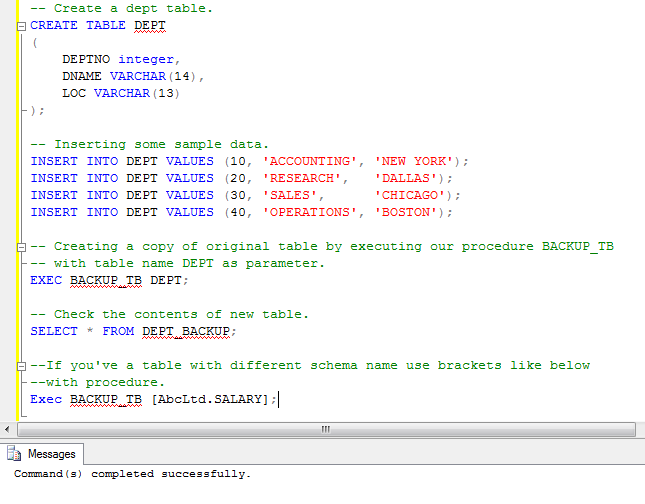
If refcolumn is omitted, the primary key of the reftable is used. The referenced columns must be the columns of a non-deferrable unique or primary key constraint in the referenced table. Note that foreign key constraints cannot be defined between temporary tables and permanent tables. The InnoDB Engine have been used to create the tables.
A clause that specifies an existing table from which the new table automatically copies column names, data types, and NOT NULL constraints. The new table and the parent table are decoupled, and any changes made to the parent table aren't applied to the new table. Default expressions for the copied column definitions are copied only if INCLUDING DEFAULTS is specified. The default behavior is to exclude default expressions, so that all columns of the new table have null defaults. These options specify the paths for data files and index files, respectively.

If these options are omitted, the database's directory will be used to store data files and index files. Note that these table options do not work for partitioned tables , or if the server has been invoked with the --skip-symbolic-links startup option. To avoid the overwriting of old files with the same name that could be present in the directories, you can use the --keep_files_on_create option . These options are ignored if the NO_DIR_IN_CREATE SQL_MODE is enabled .

Also note that symbolic links cannot be used for InnoDB tables. Use the TEMPORARY keyword to create a temporary table that is only available to the current session. Temporary tables are dropped when the session ends.

They will not conflict with other temporary tables from other sessions even if they share the same name. They will shadow names of non-temporary tables or views, if they are identical. A temporary table can have the same name as a non-temporary table which is located in the same database. In that case, their name will reference the temporary table when used in SQL statements. You must have the CREATE TEMPORARY TABLES privilege on the database to create temporary tables. If no storage engine is specified, the default_tmp_storage_engine setting will determine the engine.

The specialty of the statement is that, The ON UPDATE CASCADE action allows you to perform cross-table update and ON DELETE RESTRICT action reject the deletion. The optional SORT BY clause lets you specify zero or more columns that are sorted in the data files created by each Impala INSERT or CREATE TABLE AS SELECT operation. Creating data files that are sorted is most useful for Parquet tables, where the metadata stored inside each file includes the minimum and maximum values for each column in the file.

Impala can create tables containing complex type columns, with any supported file format. Because currently Impala can only query complex type columns in Parquet tables, creating tables with complex type columns and other file formats such as text is of limited use. Constraint that specifies that a column or a number of columns of a table can contain only unique non-null values.

Identifying a set of columns as the primary key also provides metadata about the design of the schema. A primary key implies that other tables can rely on this set of columns as a unique identifier for rows. One primary key can be specified for a table, whether as a single column constraint or a table constraint. The primary key constraint should name a set of columns that is different from other sets of columns named by any unique constraint defined for the same table. In the new table product_sold_by_order2, all the columns in the SELECT statement are appended to the right side of the extra new column ID.

This gives us the flexibility to add extra new columns without having to write and run another ALTER table query after the new table is created. The specialty of the statement is that, The ON DELETE NO ACTION and the ON UPDATE NO ACTION actions will reject the deletion and any updates. No table structure syntax (columns, data types, constraints, etc.) is involved. The new table will simply be created by using the same structure of the existing table. The new table will also contain all the data from the existing table. Constraint that specifies that a group of one or more columns of a table can contain only unique values.

The behavior of the unique table constraint is the same as that for column constraints, with the additional capability to span multiple columns. In the context of unique constraints, null values aren't considered equal. Each unique table constraint must name a set of columns that is different from the set of columns named by any other unique or primary key constraint defined for the table.
Identifying a column as the primary key provides metadata about the design of the schema. One primary key can be specified for a table, whether as a column constraint or a table constraint. ENUMTo store text value chosen from a list of predefined text valuesSETThis is also used for storing text values chosen from a list of predefined text values. Study it and identify how each data type is defined in the below create table MySQL example. If the same column name exists in more than one parent table, an error is reported unless the data types of the columns match in each of the parent tables.

If there is no conflict, then the duplicate columns are merged to form a single column in the new table. If the new table explicitly specifies a default value for the column, this default overrides any defaults from inherited declarations of the column. Otherwise, any parents that specify default values for the column must all specify the same default, or an error will be reported.

When a typed table is created, then the data types of the columns are determined by the underlying composite type and are not specified by the CREATE TABLE command. But the CREATE TABLE command can add defaults and constraints to the table and can specify storage parameters. Tables created with the LIKE option don't inherit primary and foreign key constraints.

Distribution style, sort keys, BACKUP, and NULL properties are inherited by LIKE tables, but you can't explicitly set them in the CREATE TABLE ... To see the column definitions and column comments for an existing table, for example before issuing a CREATE TABLE ... AS SELECT statement, issue the statement DESCRIBE table_name. To see even more detail, such as the location of data files and the values for clauses such as ROW FORMAT and STORED AS, issue the statement DESCRIBE FORMATTED table_name.

DESCRIBE FORMATTED is also needed to see any overall table comment . To preserve the partition information, repeat the same PARTITION clause as in the original CREATE TABLE statement. The SORT BY columns cannot include any partition key columns for a partitioned table, because those column values are not represented in the underlying data files. CHECK The CHECK clause specifies an expression producing a Boolean result which new or updated rows must satisfy for an insert or update operation to succeed. Should any row of an insert or update operation produce a FALSE result an error exception is raised and the insert or update does not alter the database.

A check constraint specified as a column constraint should reference that column's value only, while an expression appearing in a table constraint can reference multiple columns. ] The LIKE clause specifies a table from which the new table automatically copies all column names, their data types, and their not-null constraints. If refcolumn is omitted, the primary key of reftable is used. The referenced columns must be the columns of a unique or primary key constraint in the referenced table. Clause that specifies a foreign key constraint, which implies that the column must contain only values that match values in the referenced column of some row of the referenced table. The referenced columns should be the columns of a unique or primary key constraint in the referenced table.

The STORED AS clause identifies the format of the underlying data files. Currently, Impala can query more types of file formats than it can create or insert into. Use Hive to perform any create or data load operations that are not currently available in Impala. For example, Impala can create an Avro, SequenceFile, or RCFile table but cannot insert data into it. There are also Impala-specific procedures for using compression with each kind of file format. For details about working with data files of various formats, see How Impala Works with Hadoop File Formats.

TEMPORARY or TEMP If specified, the table is created as a temporary table. Temporary tables are automatically dropped at the end of a session, or optionally at the end of the current transaction . Existing permanent tables with the same name are not visible to the current session while the temporary table exists, unless they are referenced with schema-qualified names. Any indexes created on a temporary table are automatically temporary as well. Second, list all columns of the table within the parentheses.
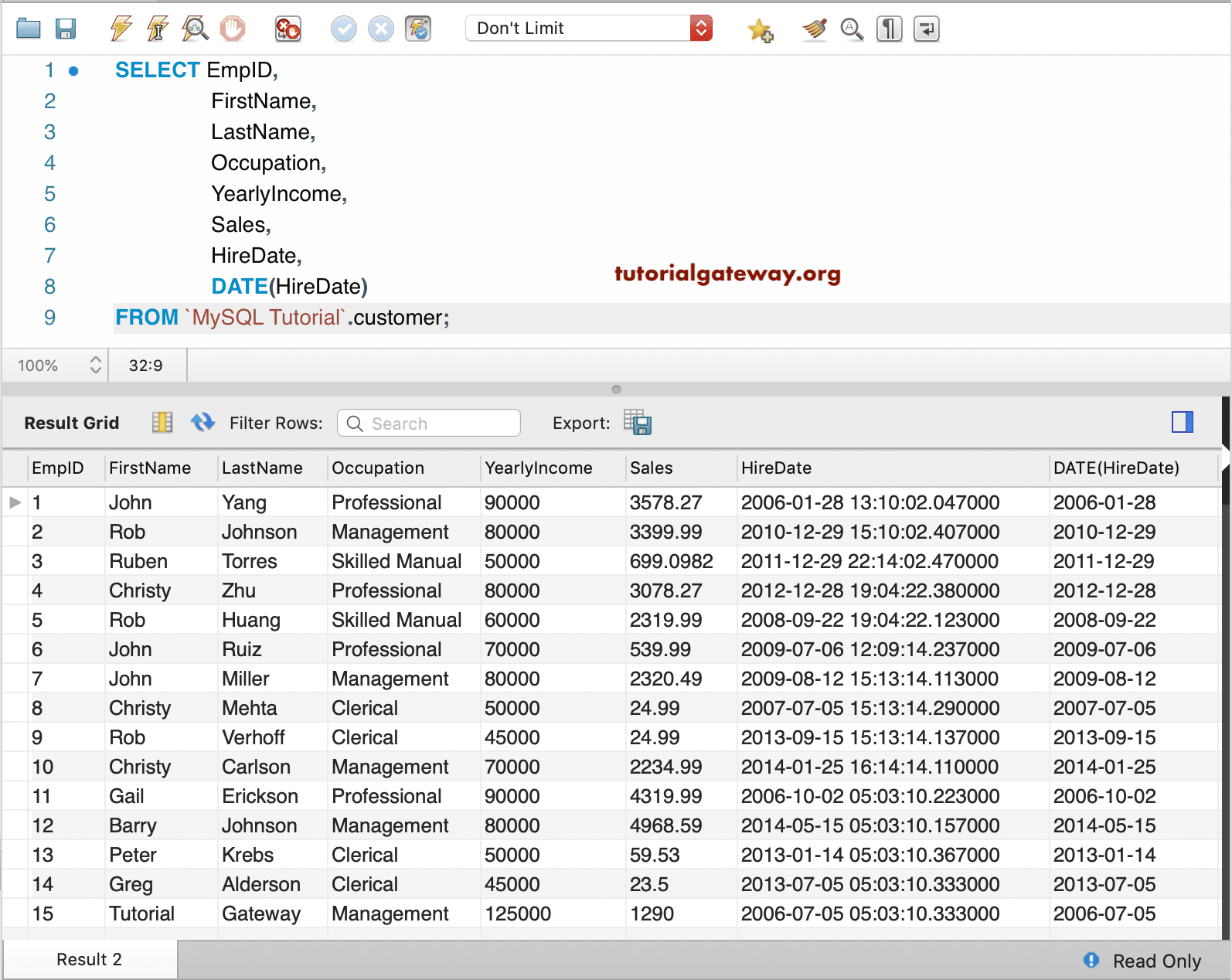
In case a table has multiple columns, you need to separate them by commas . A column definition includes the column name followed by its data type e.g., NUMBER, VARCHAR2, and a column constraint such as NOT NULL, primary key, check. Note that the difference between the ROWS_PARSED and ROWS_LOADED column values represents the number of rows that include detected errors.

However, each of these rows could include multiple errors. To view all errors in the data files, use the VALIDATION_MODE parameter or query the VALIDATE function. [,…] Invalid for external tables, specifies columns from the SELECTlist on which to sort the superprojection that is automatically created for this table. The ORDER BY clause cannot include qualifiers ASCor DESC.

The most convenient layout for partitioned tables is with all the partition key columns at the end. The CTAS PARTITIONED BY syntax requires that column order in the select list, resulting in that same column order in the destination table. In its most basic form, the CREATE TABLE statement provides a table name followed by a list of columns, indexes, and constraints. By default, the table is created in the default database. If you quote the table name, you must quote the database name and table name separately as `db_name`.`tbl_name`. SELECT, because it allows to create a table into a database, which contains data from other databases.

Clause that specifies that the column is a default IDENTITY column and enables you to automatically assign a unique value to the column. The data type for an IDENTITY column must be either INT or BIGINT. When you add rows without values, these values start with the value specified as seed and increment by the number specified as step. For information about how values are generated, see IDENTITY . DefinitionDefines the encoding format for binary string values in the data files. The option can be used when loading data into binary columns in a table.

Specifies an existing named file format to use for loading/unloading data into the table. The named file format determines the format type (CSV, JSON, etc.), as well as any other format options, for data files. If the original table is partitioned, the new table inherits the same partition key columns. Because the new table is initially empty, it does not inherit the actual partitions that exist in the original one. To create partitions in the new table, insert data or issue ALTER TABLE ... In Impala 1.4.0 and higher, Impala can create Avro tables, which formerly required doing the CREATE TABLEstatement in Hive.

See Using the Avro File Format with Impala Tables for details and examples.By default , data files in Impala tables are created as text files with Ctrl-A characters as the delimiter. For more examples of text tables, see Using Text Data Files with Impala Tables. For Kudu tables, you specify logical partitioning across one or more columns using the PARTITION BY clause. In contrast to partitioning for HDFS-based tables, multiple values for a partition key column can be located in the same partition. The optional HASH clause lets you divide one or a set of partition key columns into a specified number of buckets.
You can use more than one HASH clause, specifying a distinct set of partition key columns for each. The optional RANGE clause further subdivides the partitions, based on a set of comparison operations for the partition key columns. Table, where the data files are typically produced outside Impala and queried from their original locations in HDFS, and Impala leaves the data files in place when you drop the table. For details about internal and external tables, see Overview of Impala Tables. NO ACTION Produce an error indicating that the deletion or update would create a foreign key constraint violation. If the constraint is deferred, this error will be produced at constraint check time if there still exist any referencing rows.

The columns created in the new table are all sourced from the column definitions in the SELECT statement. MySQL determines the best data type to use for calculated columns, e.g. the TotalSales column. The SELECT query can be simple or complex, depending on your need, such as using WHERE, JOIN, UNION, GROUP BY, HAVING, etc. By default , data files in Impala tables are created as text files with Ctrl-A characters as the delimiter. The sorting aspect is only used to create a more efficient layout for Parquet files generated by Impala, which helps to optimize the processing of those Parquet files during Impala queries. With the CREATE TABLE AS SELECT and CREATE TABLE LIKEsyntax, you do not specify the columns at all; the column names and types are derived from the source table, query, or data file.

The user_id column uses values that exist in the id column of the users table in order to connect the tables through the foreign key constraint we just created. When transforming data during loading (i.e. using a query as the source for the COPY command), this option is ignored. There is no requirement for your data files to have the same number and ordering of columns as your target table. Prior to Impala 1.4.0, it was not possible to use the CREATE TABLE LIKE view_name syntax. In Impala 1.4.0 and higher, you can create a table with the same column definitions as a view using the CREATE TABLE LIKE technique. Although CREATE TABLE LIKE normally inherits the file format of the original table, a view has no underlying file format, so CREATE TABLE LIKE view_name produces a text table by default.
To specify a different file format, include a STORED AS file_format clause at the end of the CREATE TABLE LIKE statement. Of the underlying data files and moves them when you rename the table, or deletes them when you drop the table. For more about internal and external tables and how they interact with the LOCATION attribute, see Overview of Impala Tables.
With the CREATE TABLE AS SELECT and CREATE TABLE LIKE syntax, you do not specify the columns at all; the column names and types are derived from the source table, query, or data file. CREATE TABLE also automatically creates a data type that represents the composite type corresponding to one row of the table. Therefore, tables cannot have the same name as any existing data type in the same schema. AUTO_INCREMENT specifies the initial value for the AUTO_INCREMENT primary key. This works for MyISAM, Aria, InnoDB/XtraDB, MEMORY, and ARCHIVE tables.

You can change this option with ALTER TABLE, but in that case the new value must be higher than the highest value which is present in the AUTO_INCREMENT column. If the storage engine does not support this option, you can insert a row having the wanted value - 1 in the AUTO_INCREMENT column. Keyword that specifies that the column is the sort key for the table.



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.